The Autonomous Content Engine: A Technical Blueprint for Multi-Agent Media Systems
You're a builder.
You've shipped production systems. You've debugged distributed architectures at 2am.
But lately you're spending your best hours fighting the algorithm instead of building the systems that conquer it.
Your peer down the hall just published four technical posts this month. You've been stuck on one for six weeks.
They're not working harder. They're not smarter.
They wired up a system. You're still running on willpower.
Here's what I'm seeing: the era of manual content creation is winding down fast. Multi-agent pipelines now handle research, drafting, critique, and distribution while engineers focus on architecture and strategy.
You can keep being a consumer of the AI hype.
Or you can become the engineer who orchestrates it.
The Manual Synthesis Gap
Let's name what's actually happening to you.
You sit down to write. First you need research. So you open twelve tabs, skim papers, bookmark documentation. Two hours vanish. Now you're tired. The actual writing? Maybe tomorrow.
When you finally draft something, it reads flat. Generic. Missing the technical depth your audience expects. So you rewrite. Then rewrite again. Then abandon the whole thing because a production incident needs attention.
This is the Manual Synthesis Gap—the chasm between the knowledge in your head and the published artifacts that build your reputation.
The problem isn't your writing skills. The problem is cognitive architecture.
You're trying to run research, synthesis, drafting, and quality control as sequential processes in a single context window: your brain. That worked when publishing once a quarter was enough. It fails catastrophically when your peer with the agent pipeline ships weekly.
What makes this gap particularly brutal: you know you have insights worth sharing. You've solved gnarly problems. You understand systems most people can't even name. But that knowledge stays trapped because the extraction process is manual, serial, and exhausting.
Why Your Current Content Stack is a Legacy System
Think about how we used to build software before CI/CD pipelines.
Manual deployments. Tribal knowledge. "Works on my machine." A single developer as the bottleneck for every release.
Your content workflow is that legacy system. One person holding all the context. No separation of concerns. No automated quality gates. No way to parallelize.
The teams shipping consistently have moved past this. They're treating content like infrastructure—automated, observable, version-controlled.
The shift isn't from "AI-assisted" to "AI-generated." It's from monolithic authoring to agentic orchestration. From single-threaded cognition to parallel processing with specialized components.
The Manufacturing Mindset
"The best architectures, requirements, and designs emerge from self-organizing teams." — Agile Manifesto (2001)
That principle applies to agent teams too.
From our experience building these systems: you don't want one massive prompt trying to do everything. You want specialized agents with narrow responsibilities, communicating through structured artifacts.
A Research Agent that queries vector databases and synthesizes evidence. A Draft Agent that transforms structured research into narrative. A Critic Agent that evaluates against explicit rubrics. A Revision Agent that applies feedback surgically.
Here's what I mean by "cyclical reasoning" in practice: your Draft Agent generates a section, the Critic detects a missing API detail, control flows back to the Research node to patch the fact manifest, then forward again to regenerate that section. The graph loops until quality thresholds pass.
This mirrors how strong engineering teams actually work. Nobody expects one person to architect, implement, review, and deploy. You distribute cognitive load across specialists.
The same principle makes content pipelines reliable. Separation of concerns isn't just good software design—it's how you make AI systems predictable.
The Protocol: Building Your Autonomous Engine
Step 1: Start With the Critic, Not the Writer
Everyone wants to build the flashy draft agent first. Resist that impulse.
Your critic is your test suite. Build it first.
Define explicit quality rubrics before you generate a single paragraph. What counts as technically accurate? What voice patterns match your brand? What structural elements must every piece contain?
From our implementation: we score drafts on technical accuracy, clarity, code correctness, and persona alignment. Each dimension gets a 1-5 rating. If the aggregate falls below threshold, the draft routes back for revision automatically.
The concrete action: create a CritiqueResult schema this weekend. Include technical_accuracy, clarity_score, code_examples_valid (boolean), and issues (list of strings). Run it manually against your last three blog posts. Notice what it catches.
This is your smallest deployable loop. A critic with a checklist.
Step 2: Build the Fact Manifest
Single-shot generation fails for technical content. Not sometimes. Predictably.
When you ask an LLM to write a 2,000-word technical post in one pass, you're overloading a finite context window with research, structure, style, code examples, and narrative coherence simultaneously. The failure modes are obvious once you look: wrong library versions, deprecated API calls, citations to documentation that doesn't exist.
The fix is separation. Research produces a Fact Manifest before drafting begins.
Think of the Fact Manifest as a build artifact. It contains verified claims, code snippets, source URLs, and explicit gaps flagged for further research. Your Draft Agent consumes this artifact—it doesn't conduct research.
{
"topic": "LangGraph State Persistence",
"key_claims": [
{
"claim": "PostgreSQL checkpointing enables resumable workflows",
"source": "docs.langchain.com/langgraph/persistence",
"verified": true
}
],
"code_examples": [...],
"knowledge_gaps": ["unclear on Redis vs Postgres tradeoffs"]
}
This grounding eliminates the hallucination category that kills technical credibility. Every statement traces back to source.
The concrete action: for your next post, spend the first session only building the Fact Manifest. No drafting. Just structured research. See how differently the writing flows when you're assembling from verified components instead of synthesizing from memory.
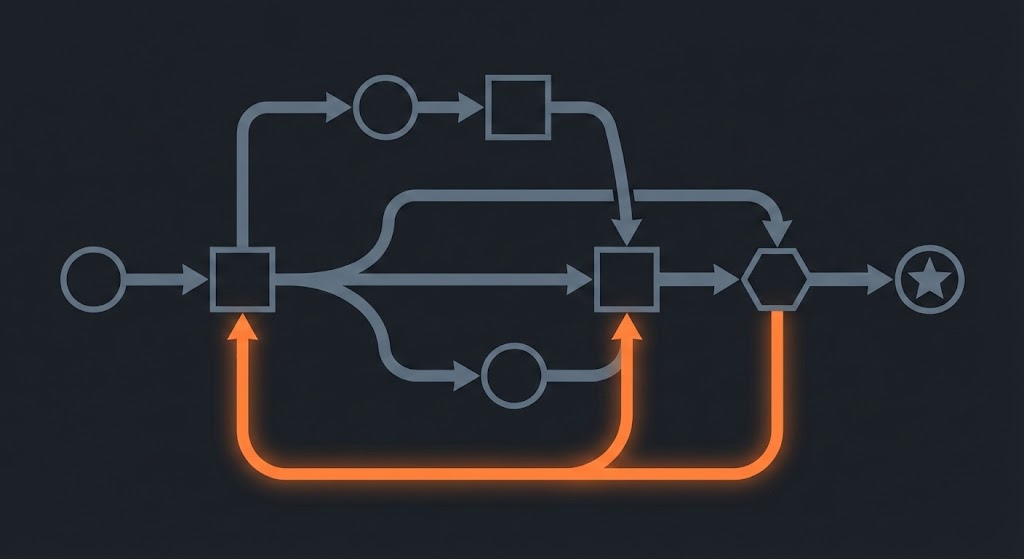
Step 3: Wire the Graph (But Start Simple)
You don't need the full LangGraph state machine on day one.
Start with three nodes: Research → Draft → Critique. Add a conditional edge: if critique_score < 4.0, route back to Draft with feedback attached. Otherwise, proceed to end.
The graph pattern matters more than the specific framework. You want explicit state that flows between nodes. You want conditional routing based on quality signals. You want the ability to pause, inspect, and resume.
From our experience: we run two parallel tracks. A fully autonomous LangGraph workflow handles batch processing overnight. A staged pipeline with human checkpoints handles higher-stakes pieces. The architecture lets us dial autonomy up or down per content type.
What makes LangGraph worth the learning curve: checkpointing. When your Draft Agent hits a rate limit at 2am, the workflow persists state to Postgres, waits for the API to recover, and resumes exactly where it stopped. No lost work. No manual restart.
The concrete action: sketch the three-node graph on paper. Label the edges with conditions. Identify where you'd want a human approval gate. This design session costs an hour and saves weeks of rework.
Step 4: Implement the Rate Limit Dance
Here's the tricky part nobody warns you about.
Autonomous pipelines hit rate limits. A lot. You're making dozens of LLM calls per article, across multiple providers, often in parallel. Without explicit handling, your workflow crashes and you're back to manual recovery.
The pattern that works: catch the 429, update state with retry_after and error_source, route to a dedicated Wait node that sleeps without consuming compute, then route back to the original node. Exponential backoff prevents API hammering.
# Pseudocode for the retry pattern
if response.status == 429:
state["status"] = "rate_limited"
state["retry_after"] = response.headers["Retry-After"]
return route_to("wait_node")
The Wait node is boring but essential. It doesn't call any LLM. It just sleeps, then routes back. Your workflow becomes resilient to the API flakiness that plagues production systems.
Verify this against your specific LangGraph version—APIs evolve. The pattern stays stable: checkpointing, resumability, idempotent nodes, explicit wait states.
Step 5: Add the Human-in-the-Loop Dial
Full autonomy sounds appealing until you publish something wrong.
The realistic architecture includes interrupts. After critique, before publish, the workflow pauses. A webhook fires to Slack. An editor reviews. They click approve or reject with feedback. The graph resumes.
This isn't a failure of automation—it's production-grade design. You're not replacing humans. You're compressing their work from "write everything" to "verify the 10% that matters."
From our implementation: we use a 0-100 quality dial. Above 85, auto-approve. Between 70-85, notify for review. Below 70, route back for revision without human intervention. The thresholds tune over time as the system learns what passes muster.
The concrete action: define your approval threshold. Where does your risk tolerance sit? Start conservative (low auto-approve threshold), then dial up as you build confidence.
Step 6: Engineer Readability, Not Detector Evasion
Your draft will sound like an LLM at first. Fix that with explicit constraints, not tricks.
I'm not talking about beating AI detectors. I'm talking about craft. Real readability. The kind that keeps engineers reading instead of bouncing.
The symptoms of LLM prose: monotonous sentence rhythm, excessive hedging, generic transitions ("Moreover," "Furthermore"), and the rule of three showing up constantly. These patterns bore human readers before any detector gets involved.
The fix: add variety requirements to your prompts. Mandate sentence length variance. Blacklist fifty common AI phrases. Require specific numbers, named tools, concrete examples instead of abstract claims.
# Prompt constraints we actually use
- Vary sentence length: mix 5-word punches with 30-word explanations
- Never use: Furthermore, Moreover, Ultimately, Consequently
- Every claim needs a specific example or citation
- No paragraph-ending summary sentences
A side effect is it won't trip obvious detector heuristics. But the primary goal is voice quality control—the kind of writing that sounds like a person with opinions, not a committee trying to please everyone.
Step 7: Build Artifact Versioning From Day One
You will iterate. Plan for it.
Every draft, every critique, every revision lives in version control. When the third revision regresses quality, you can diff against v2 and see exactly what broke. When a reader points out an error, you can trace the lineage back to which research claim was wrong.
From our implementation: we store artifacts with parent_version_id, enabling lineage tracking across the full pipeline. The Outline Agent's output links to the Research Agent's output. The Draft links to both. When something fails, we trace the chain.
This isn't overhead—it's debugging infrastructure. Content pipelines are software systems. Treat them like it.
The MVP Path
You don't need to build the full system to start capturing value.
Week 1: Critic + Checklist
- Define your CritiqueResult schema
- Run it manually against existing posts
- Identify the patterns your content consistently misses
Week 2: Fact Manifest + Draft
- Build the research-first workflow
- Separate evidence gathering from prose generation
- Notice how grounding reduces revision cycles
Week 3: Checkpointing + HITL
- Add persistence so failures don't lose work
- Wire the human approval gate
- Set your quality threshold conservatively
That's the smallest deployable loop. Critic, manifest, approval gate. Everything else layers on top.
The Identity Shift
You're not learning a new tool. You're becoming a different kind of engineer.
The manual synthesis gap doesn't close by working harder. It closes by building systems that work for you. The same leverage mindset that made you effective at distributed systems applies here.
Content becomes infrastructure. Quality becomes a CI/CD concern. Distribution becomes a deployment pipeline.
Your Fact Manifest is a build artifact. Your Critic Agent is your test suite. Your checkpointing layer is fault tolerance.
The engineers who figure this out first build compounding advantages. While others grind through manual drafts, you're iterating on the system that produces drafts. The gap widens every week.
This is what I'm building toward. An autonomous engine that handles the synthesis while I focus on the architecture and strategy.
Build the critic this weekend. Ship one post with a Fact Manifest. That's the on-ramp.
Stop being a spectator in the AI age.
Stay tuned for more updates from the agentic frontier.
Start building your autonomous engine today.
— Ulver
Further Reading
LangGraph Persistence and Human-in-the-Loop — docs.langchain.com/langgraph/persistence Core documentation for checkpointing patterns and interrupt mechanisms. Start here for the resumability architecture.
G-Eval: NLG Evaluation using GPT-4 — arxiv.org/abs/2303.16634 The foundational paper on using LLMs as judges. Essential for building your critic agent with principled evaluation rubrics.
CrewAI Documentation — docs.crewai.com Alternative framework with role-based agent design. Faster to prototype than LangGraph, good for initial experiments.
Multi-Agent Debate (MIT/Google) — composable-models.github.io/llm_debate Research on using agent debate to improve factual accuracy. Relevant if you're building consensus mechanisms between critics.
Anthropic's Model Context Protocol — modelcontextprotocol.io The emerging standard for agent-tool integration. Worth understanding even if you're not adopting immediately.
LangSmith Observability — docs.langchain.com/langsmith Tracing and debugging for agent systems. Essential for production—you need to see what your agents actually did when something breaks.
Sources
[1] https://docs.langchain.com/oss/python/langgraph/persistence [2] https://docs.langchain.com/oss/python/langgraph/add-memory [3] https://docs.langchain.com/langsmith/rate-limiting [4] https://docs.langchain.com/oss/python/langchain/human-in-the-loop [5] https://arxiv.org/abs/2303.16634 (G-Eval) [6] https://composable-models.github.io/llm_debate/ [7] https://www.datacamp.com/tutorial/crewai-vs-langgraph-vs-autogen [8] https://sparkco.ai/blog/langgraph-vs-crewai-vs-autogen-2025-production-showdown [9] https://www.confident-ai.com/blog/g-eval-the-definitive-guide [10] https://galileo.ai/blog/g-eval-metric [11] https://developer.nvidia.com/blog/how-small-language-models-are-key-to-scalable-agentic-ai/ [12] https://modelcontextprotocol.io